优化
- 针对小目标,精度提升。使用不同比例的盒子(
3-d tensor)+FPN网络结构。
效果
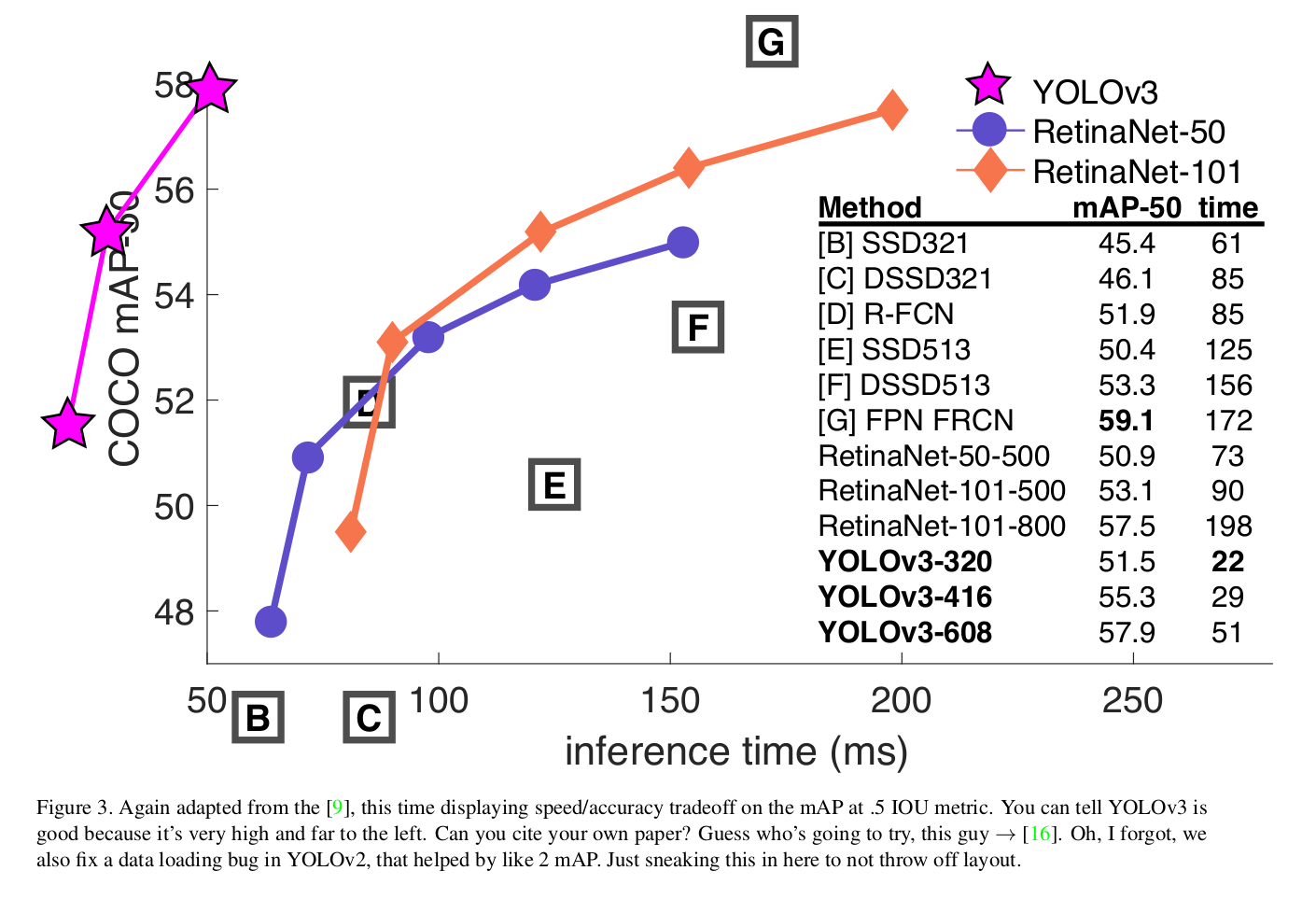
『mAP、耗时』
网络
『网络结构』
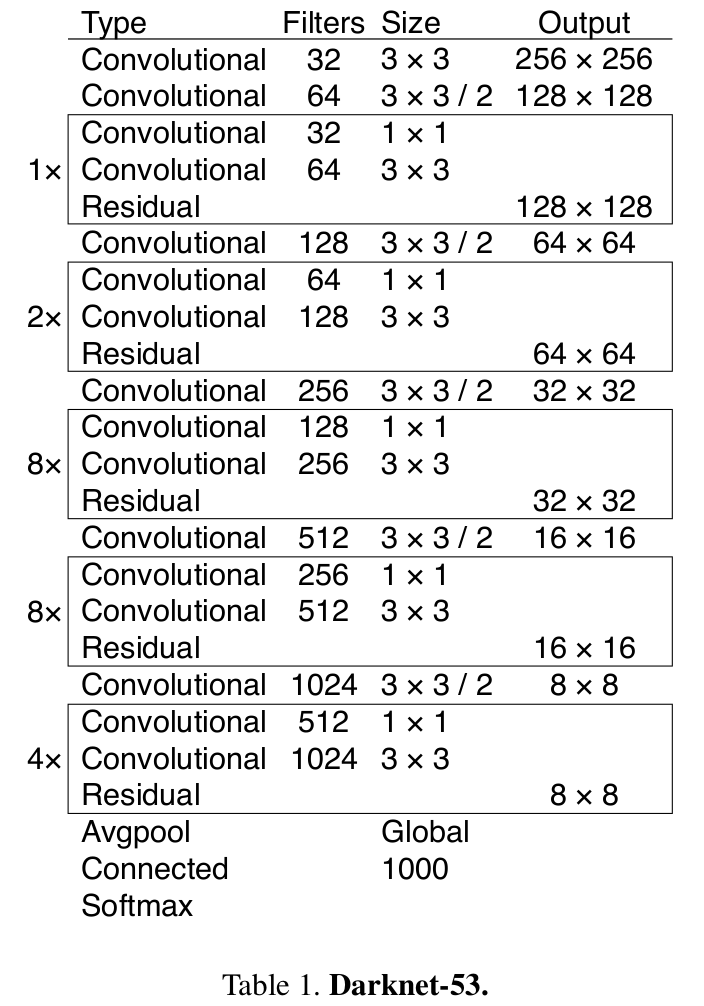
包含最后一层Connected,共53层。
yolov1: 24 conv + 2 fc ->yolov2: 19 conv ->yolov3: 52 conv + 1 fc
『基于residual的Darknet-53 与 ResNet比较』
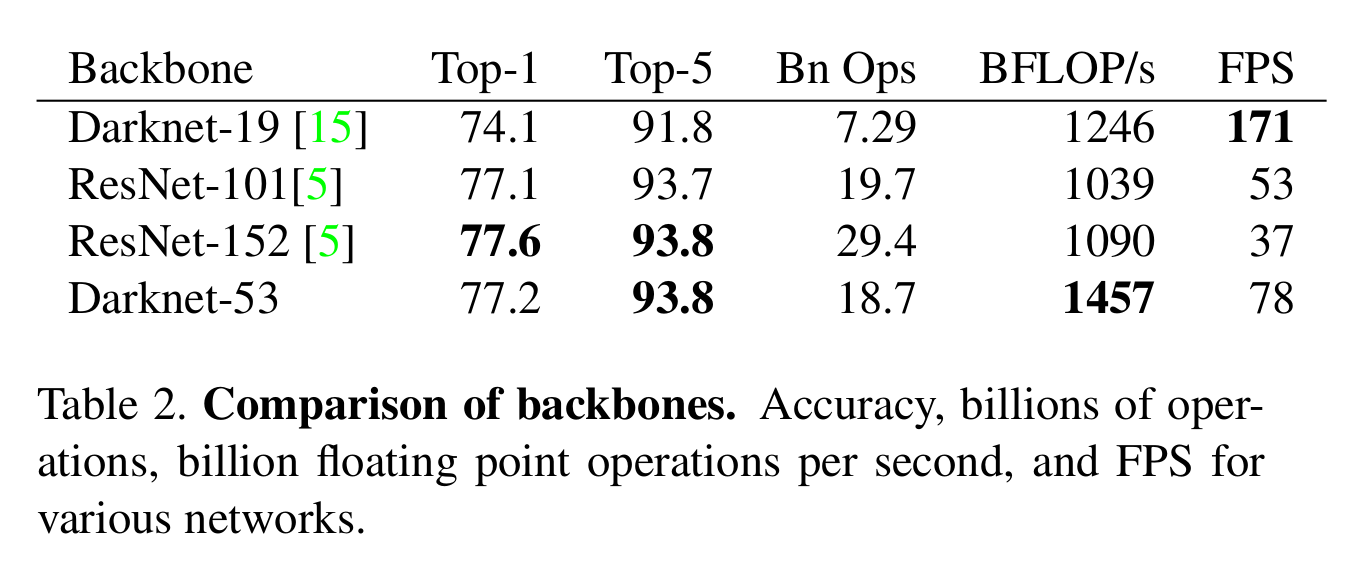
Darknet-53 采用了residual的结构,但去掉了许多认为没有效率的层。
思路
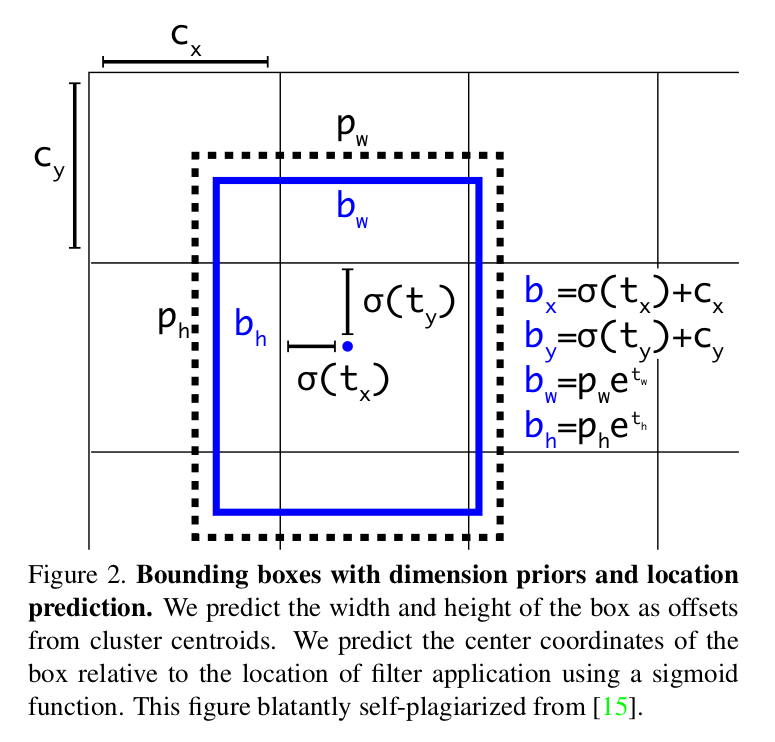
1.Bounding Box Prediction
边界盒的预测与前作一直,预测的仍然是相对prior box的偏移值。
『Bounding Box Prediction』
2.Class Prediction
改动?
发现softmax不是必要的,就将softmax层替换为1x1 conv+logistic。
训练期间,使用二分类交叉熵损失(binary cross-entropy loss)做损失。
原因?
在数据集中,有许多重叠的标签,使用softmax会假设每个盒子只有一个class,softmax不好进行拟合。
3.Predictions Across Scales
为了检测不同大小的物体,预测3种大小的bounding box,输出向量维度:N x N x [3 * (4+1+80)]。
- 3: 3 scale
- 4: bounding box offsets
- 1: objectness prediction
- 80: class predictions
训练时,某个
ground truth对应的bounding box中心落入输入图像分割的grid cell中,这个grid cell对应的objectness score就赋予1,其余赋予0。并且,每个grid cell还设了3个不同大小的prior box,学习过程中,grid cell会逐渐学会选择哪一个大小的prior box。
同时,还继续沿用了k-means获取不同比例的prior box。
在COCO数据集中,选用了9簇:(10x13), (16x30), (33x23), (30x61), (62x45), (59x119), (116x90), (159x198), (373x326)
4.Feature Extractor
原因?
通常一幅图像包含不同的物体,有大有小,期望网络具备能够”看到”不同大小的物体。理想情况下是,不同深度的feature map,浅层的feature map尺寸大,应该能看到更小的物体,而深层的feature map尺寸小,应该能看到更大的物体。
但可视化feature map告诉我们,浅层的feature map主要是包含低级的边缘、纹理等信息,而深层的feature map包含比较高级的抽象信息,如猫狗等。因此,不同深度的feature map包含的信息不一定一致,所以通过不同深度的尺寸不一的feature map,对各个卷积层的特征利用没那么好。
优化?
yolo v3采用FPN结构来提高不同scale的精度。
『Pyramid』
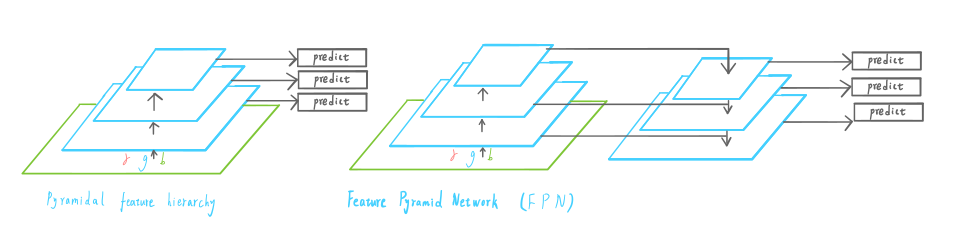
FPN中,当前feature map会对后面层的feature map进行上采样,并利用。将低级特征和高级特征结合起来。
训练
延续前作,使用multi-scale training、data augmentation、batch normalization。
note
作者提到,IOU阈值设为0.5时,YOLOv3非常强大。它几乎与RetinaNet相当,并且远远超过SSD变体。这表明YOLOv3是一款非常强大的检测器,擅长于为物体制造出合适的盒子。但是,随着IOU阈值的增加,性能会显着下降,这表明YOLOv3难以使框与对象完美对齐。