优化
本作结合了最新的研究成果,优化了各个部分:Object detection models, Bag of freebies, Bag of specials。没有改变模型思路,增加了不少提升模型精度,而没有/只有一点增加开销的trick。
效果
『effect』
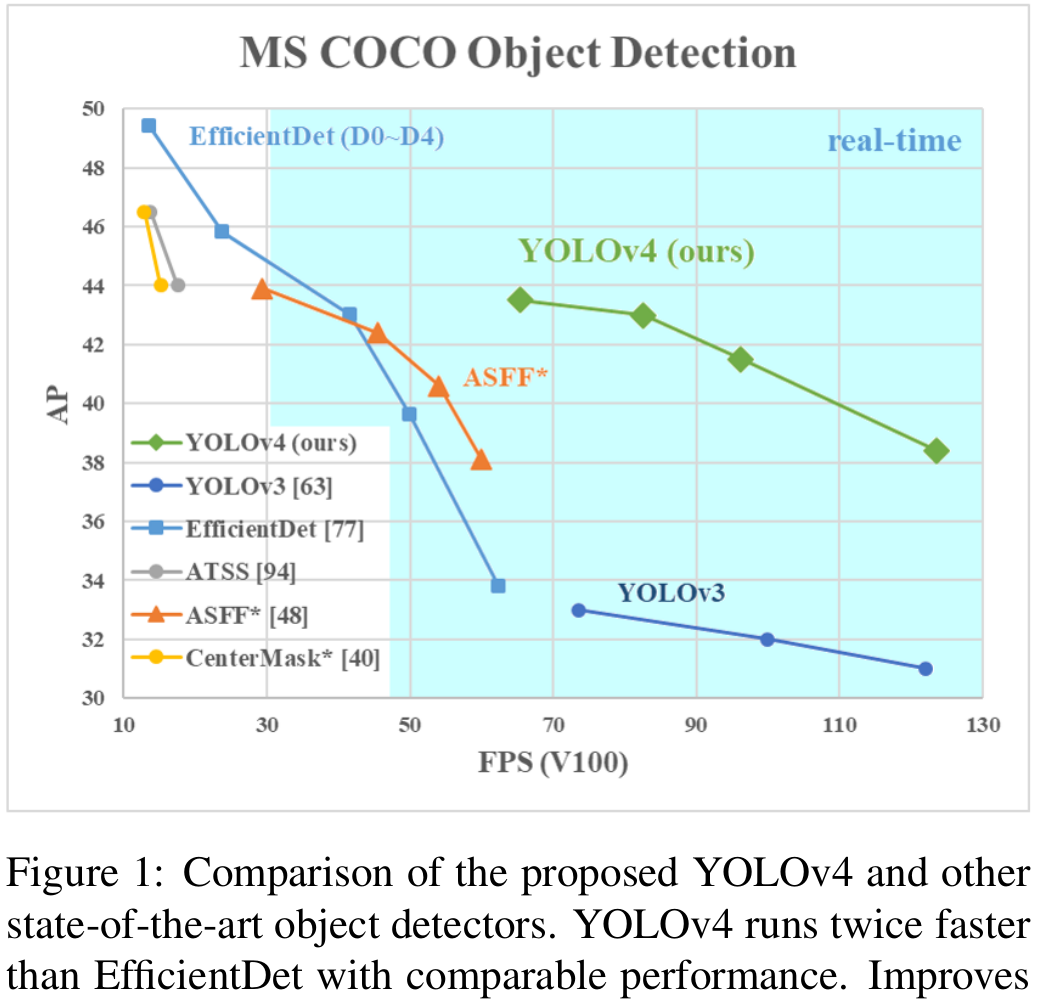
思路
『detector架构』
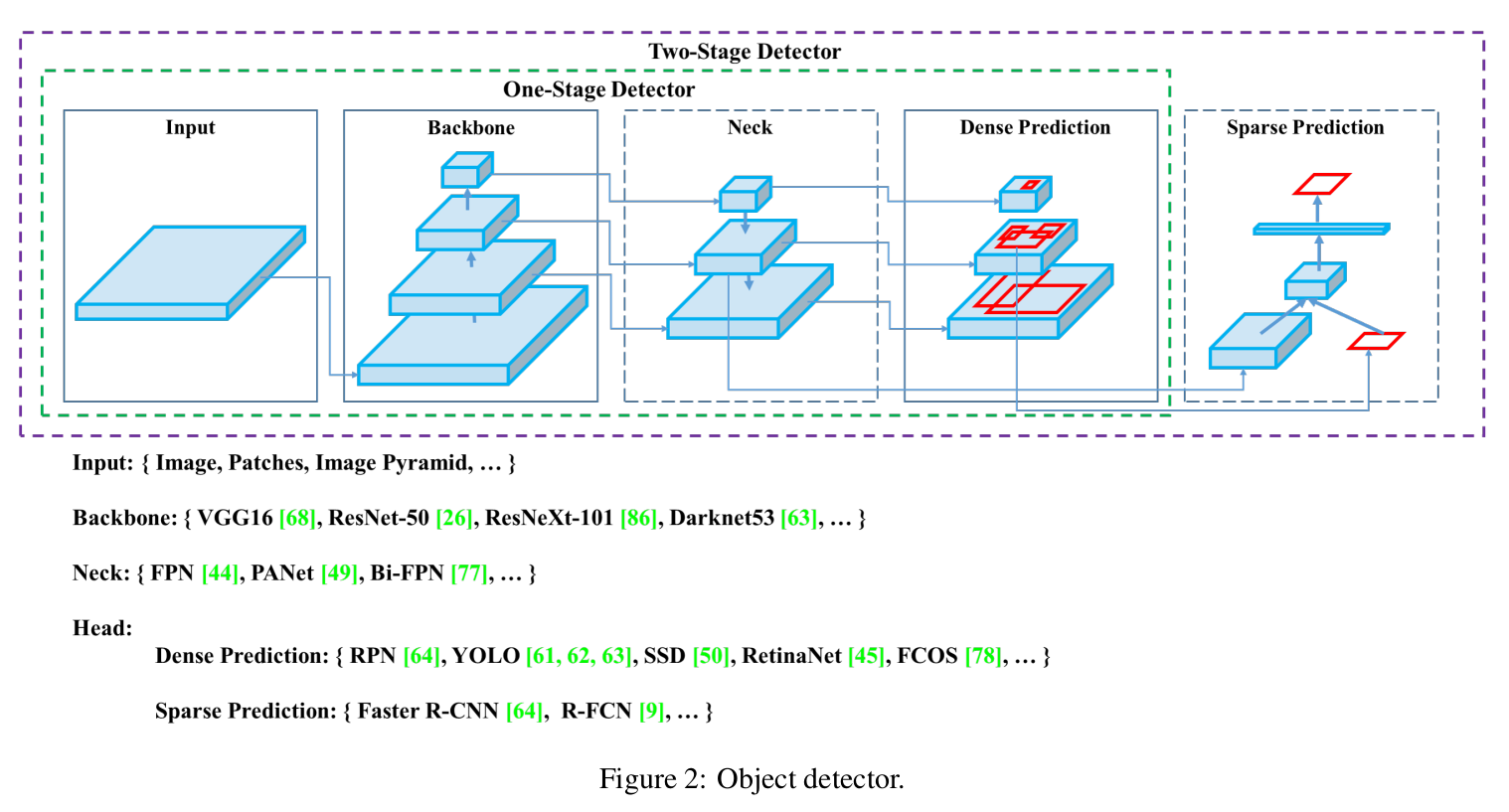
组件:
- Input:
Image,Patches,Image Pyramid - Backbones:
VGG16,ResNet-50,SpineNet,EfficientNet-B0/B7,CSPResNeXt50,CSPDarknet53 - Neck:
-
- Additional blocks:
SPP,ASPP,RFB,SAM
- Additional blocks:
-
- Path-aggregation blocks:
FPN,PAN,NAS-FPN,Fully-connected FPN,BiFPN,ASFF,SFAM
- Path-aggregation blocks:
- Heads:
-
- Dense Prediction (one-stage):
-
-
RPN,SSD,YOLO,RetinaNet(anchor based)
-
-
-
CornerNet,CenterNet,MatrixNet,FCOS(anchor free)
-
-
- Sparse Prediction (two-stage):
-
-
Faster R-CNN,R-FCN,Mask R-CNN(anchor based)
-
-
-
RepPoints(anchor free)
-
Object detection models
1.backbone
GPU平台:VGG, ResNet, ResNeXt, DenseNet。
CPU平台:SqueezeNet, MobileNet, ShuffleNet。
2.two-stage object detector
anchor based:R-CNN, fast R-CNN, faster R-CNN, R-FCN, Libra R-CNN。
anchor free:RepPoints。
3.one-stage object detector
anchor based:RPN, YOLO, SSD, RetinaNet。
anchor free:CornerNet, CenterNet, MatrixNet, FCOS。
4.collect feature maps from different layers
Feature Pyramid Network(FPN), Path Aggregation Network(PAN), BiFPN, NAS-FPN。
Bag of freebies
(白嫖:无开销增加精度)
1.photometric distortion
brightness, contrast, hue, saturation, noise。
2.geometric distortion
random scaling, cropping, flipping, rotating。
3.object occlusion issue
random erase, CutOut。
4.hide-and-seek and grid mask
随机或均匀地选择图像中的多个矩形区域,并将其替换为全零。
5.(hide-and-seek for)feature maps
DropOut, DropConnect, DropBlock。
6.using multiple images together to perform data augmentation
MixUp, CutMix。
其它数据增强:
style transfer GAN。
7.data imbalance
focal loss。
example mining方法不适用于one-stage的decector,因为这种detector种类属于密集型预测架构。
focal loss可用于解决one-stage的数据不平衡问题。
8.one-hot hard representation
one-hot难表示不同类别的关联程度,处理方案有通过将hard label转换为soft label。
9.bounding box regression
传统方法
使用Mean Square Error(MSE)去直接回归预测坐标($(x_{center}, y_{center}, w, h)$或$(x_\text{top_left}, y_\text{top_left}, x_\text{bottom_right}, y_\text{bottom_right})$)。
anchor-based方法,是估计对应的偏移($(x_\text{center_offset}, y_\text{center_offset}, w_\text{offset}, h_\text{offset})$或$(x_\text{top_left_offset}, y_\text{top_left_offset}, x_\text{bottom_right_offset}, y_\text{bottom_right_offset})$)。
直接预测坐标,把这些点作为独立的变量,没有考虑到对象的完整性。
最近的研究
使用IoU loss,以预测的BBox和标签的覆盖范围来考虑。能解决传统方法的问题 – loss随着box尺寸的增大而增大。(小对象难以训练)
GIoU loss包含对象的形状和方向附加到覆盖区域。
DIoU loss考虑对象中心的距离。
CIoU loss同时考虑覆盖范围、中心点的距离、长宽比。(能完成更好的收敛速度和精度)
Bag of specials
(只增加一丢丢推理开销,增加精度)
目的是enhancing certain attributes。
1.enhance receptive field
SPP, ASPP, RFB。(SPP源于Spatial Pyramid Matching(SPM))
SPP会输出一维特征向量,所以不能直接用于全卷积的yolov3中。通过级联k={1, 5, 9, 13}的max-pooling,和stride=1,得以应用。
2.attention mechanism
主要用于分离channel-wise attention和point-wise attention。
Squeeze-and-Excitation(SE), Spatial Attention Module(SAM)。
3.feature integration
特征整合的2个方向:skip connection, hyper-column。去整合低级的物理特征到高级的语义特征。
FPN开始热门后,出现轻量化模块SFAM, ASFF, BiFPN。
SFAM使用SE模块,ASFF使用softmax,BiFPN使用multi-input weighted residual connections。
4.activation function
(传统tanh和sigmod梯度消失问题,)ReLU实质解决梯度消失后,出现LReLU, PReLU, ReLU6, Scaled Exponential Linear Unit(SELU), Swish, hard-Swish, Mish。
不仅解决梯度消失的问题,LReLU和PReLU还解决了ReLU零输出的问题。
5.post-processing method
NMS非极大值抑制用于过滤同一个目标不好的预测框,保留BBox高响应的候选框。
NMS的问题在于没有考虑到上下文信息,后提出了soft NMS,考虑目标遮挡的问题。
在soft NMS的基础上,DIoU NMS添加中心点距离信息到BBox筛选流程。
anchor-free方式不再考虑后期处理。
功能选择
1.Selection of architecture
相对于classifier,detector需要?
- 更高的输入分辨率 – 为了检测多的小目标
- 更多层 – 为了更高的感受野去覆盖更大的输入分辨率
- 更多参数 – 更好的模型容量去检测多个不同尺寸的目标
如下表得出,
CSPDarknet53的层多, 感受野大, 参数多。
『不同的backbone model比较』

不同大小的感受野的影响?
- 提高目标尺寸 – 允许看到整个目标
- 提高网络尺寸 – 允许看到目标周围的上下文
- 超过网络尺寸 – 增加图像点和最终激活的连接数量
- 在CSPDarknet53上添加
SPP块,增加感受野,分离出最重要的上下文特征。(且几乎没有降低速度)- 使用
PANet作为参数聚合,替代yolov3使用的FPN。
2.Selection of BoF and BoS
为了提高目标检测的训练,CNN通常使用如下方式:
- Activations: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method: DropOut, DropPath, Spatial DropOut, or DropBlock
- Normalization of the network activations by their mean and variance: Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN)
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
- ReLU6专为量化网络设计,PReLU和SELU难训练。
- DropBlock远比其它好。
- SyncBN是用于多个GPU的,这里不考虑。
3.Additional improvements
为了使detector更适合单GPU训练,做了一些改进:
- 使用新的数据增强方式:
马赛克,SAT自对抗训练。 - 使用
遗传算法选择最佳超参数。 - 修改一些已有的方法,使其更适合有效的训练和检测:
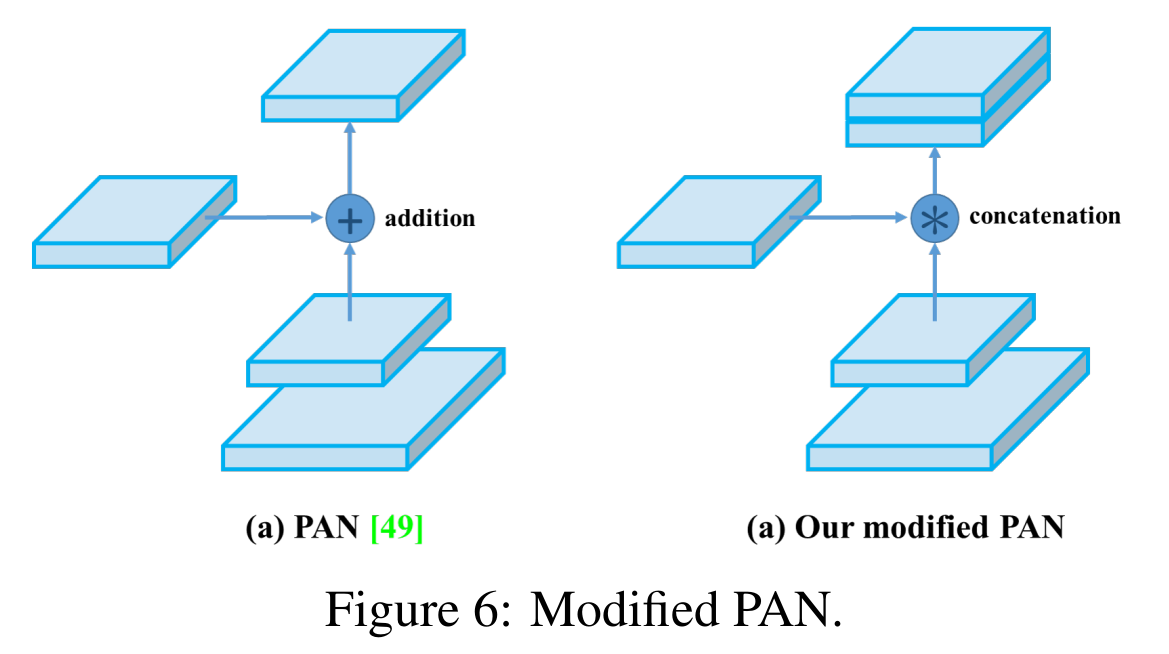
修改的SAM,修改的PAN,CmBN交叉小批量归一化。
『改进图示』

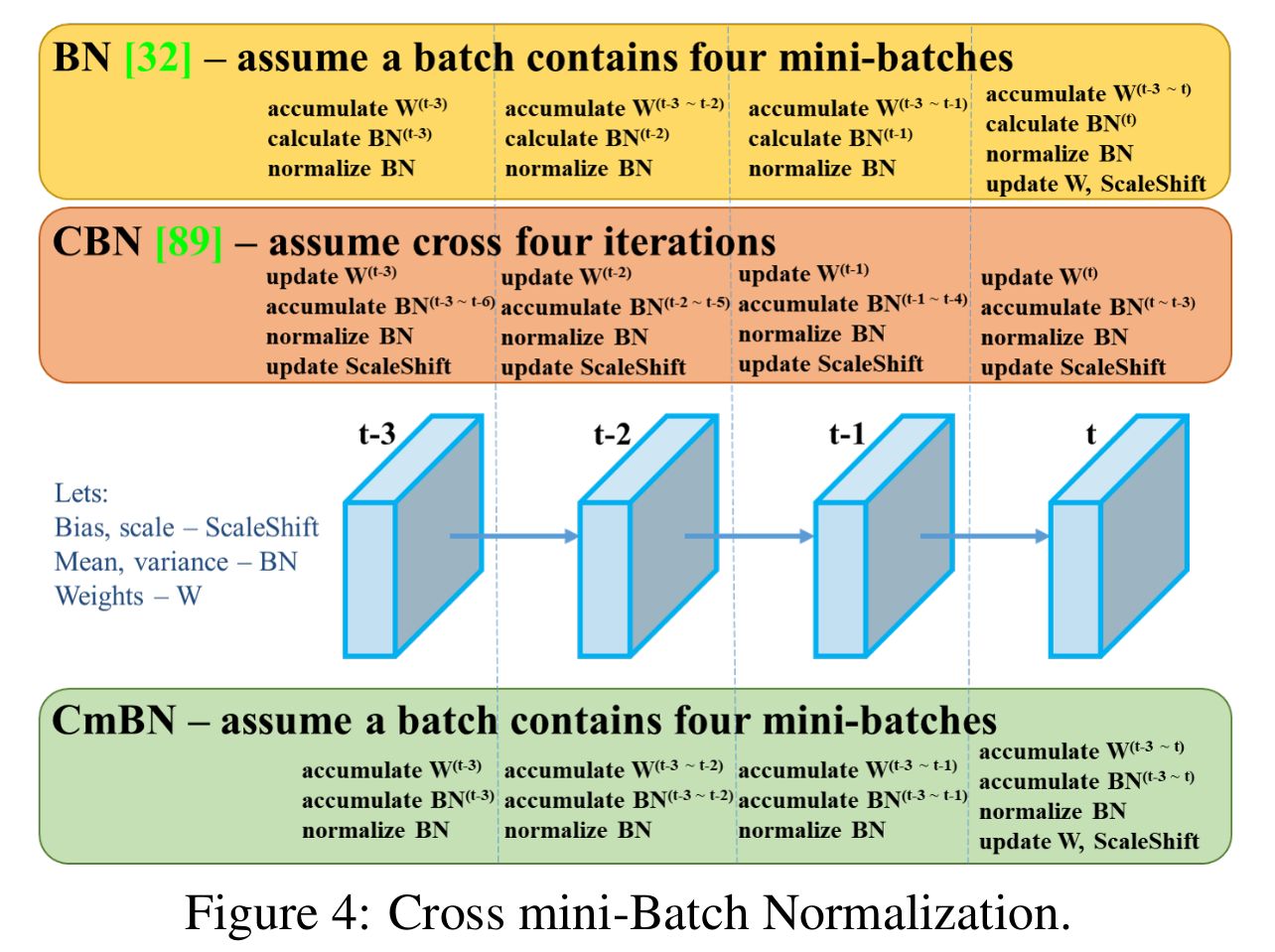
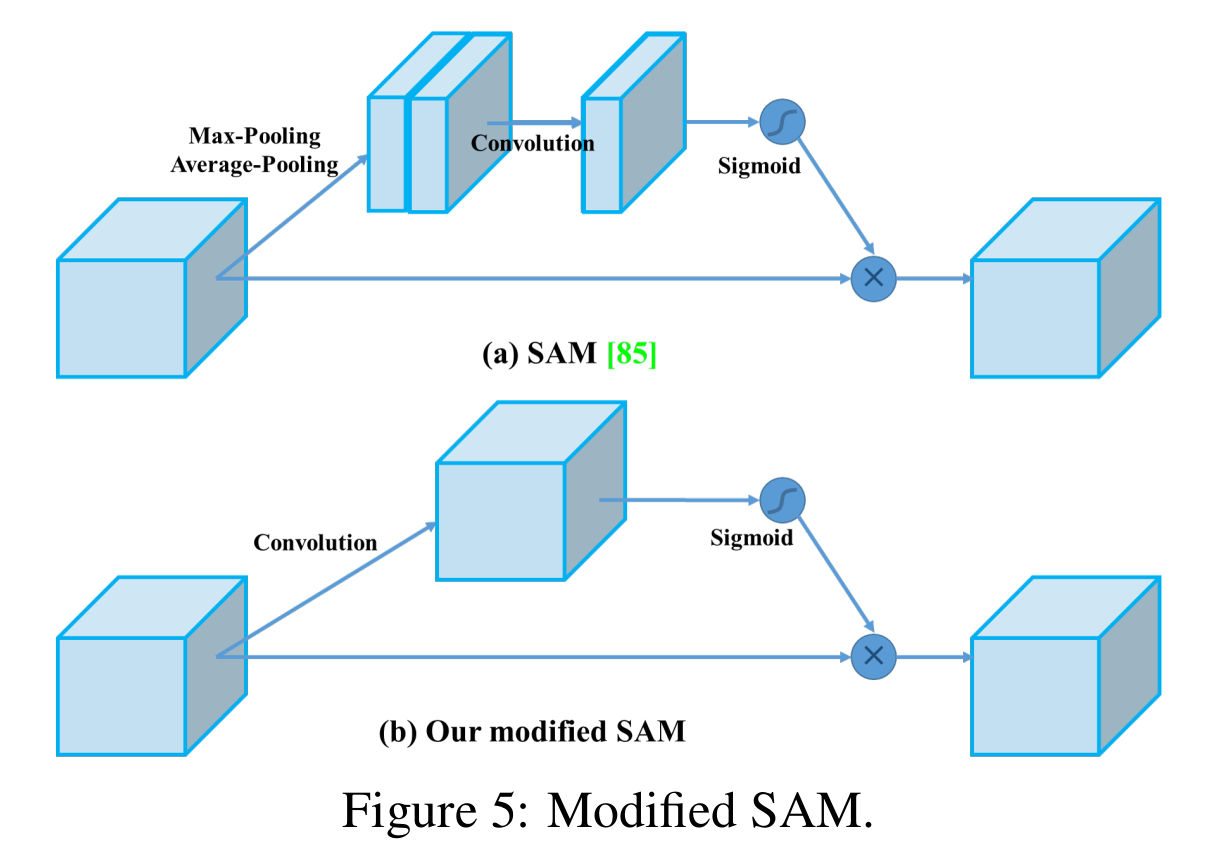
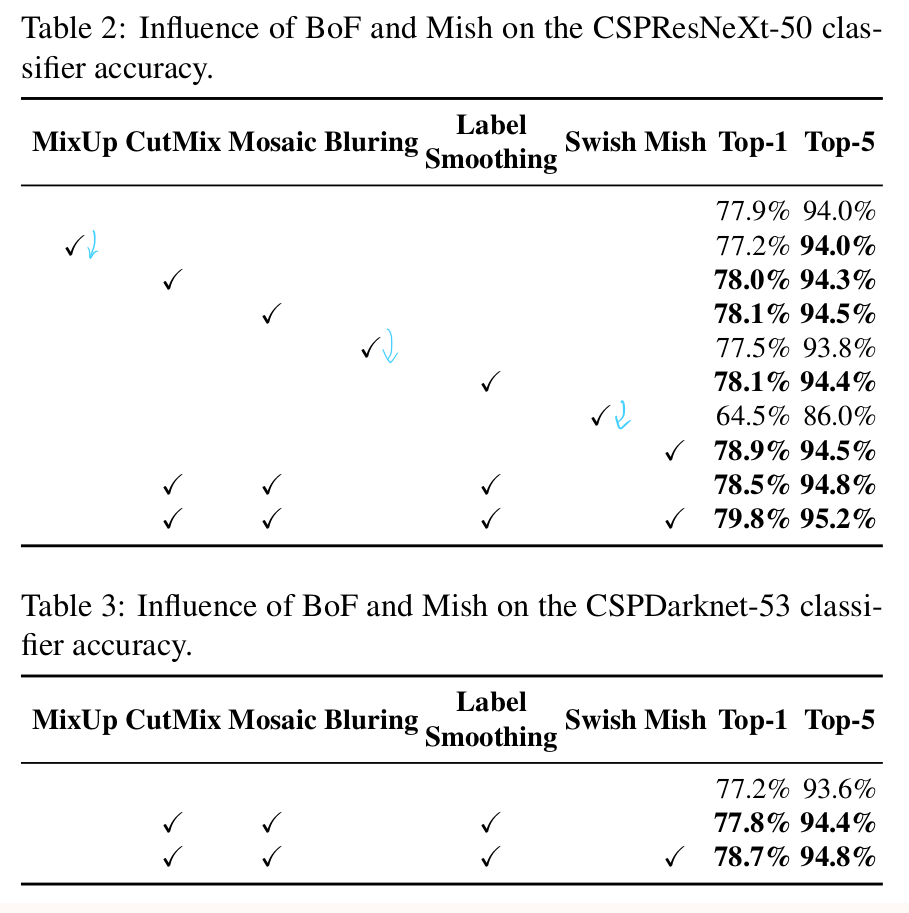
实验
不同功能对classifier训练的影响
『数据增强』

『BoF和Mish对classifier的影响』
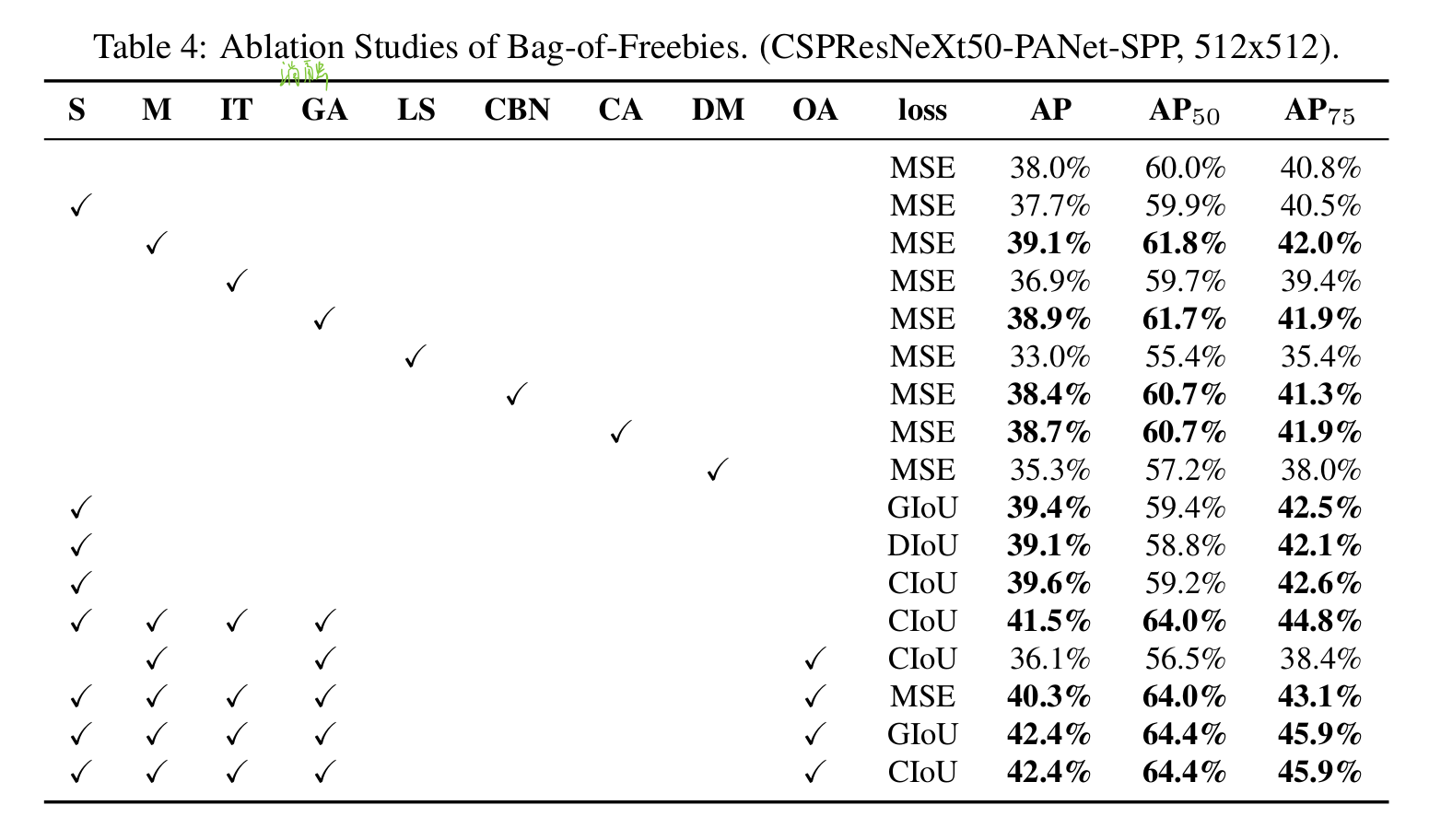
不同功能对detector训练的影响
『BoF对detector的影响』
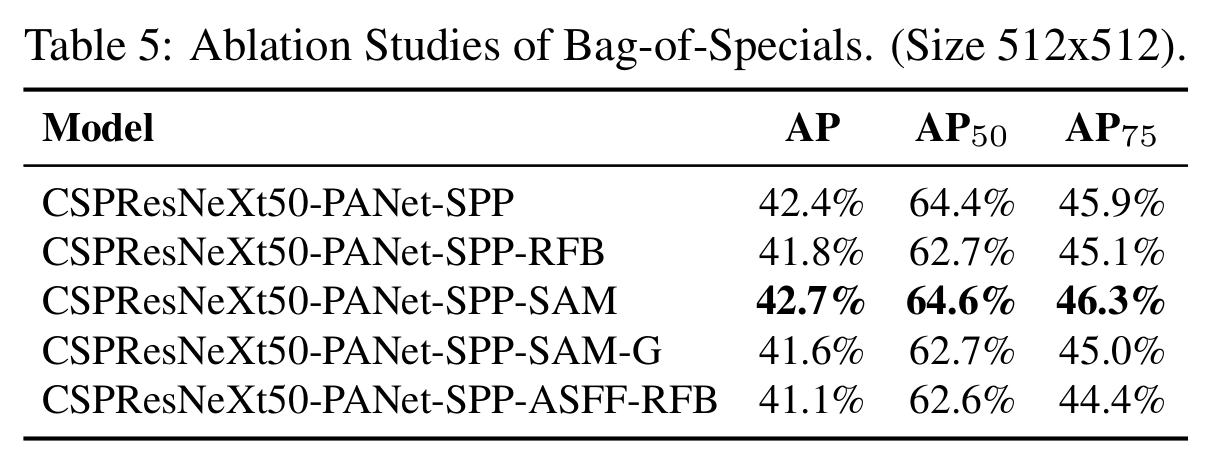
『BoS对detector的影响』
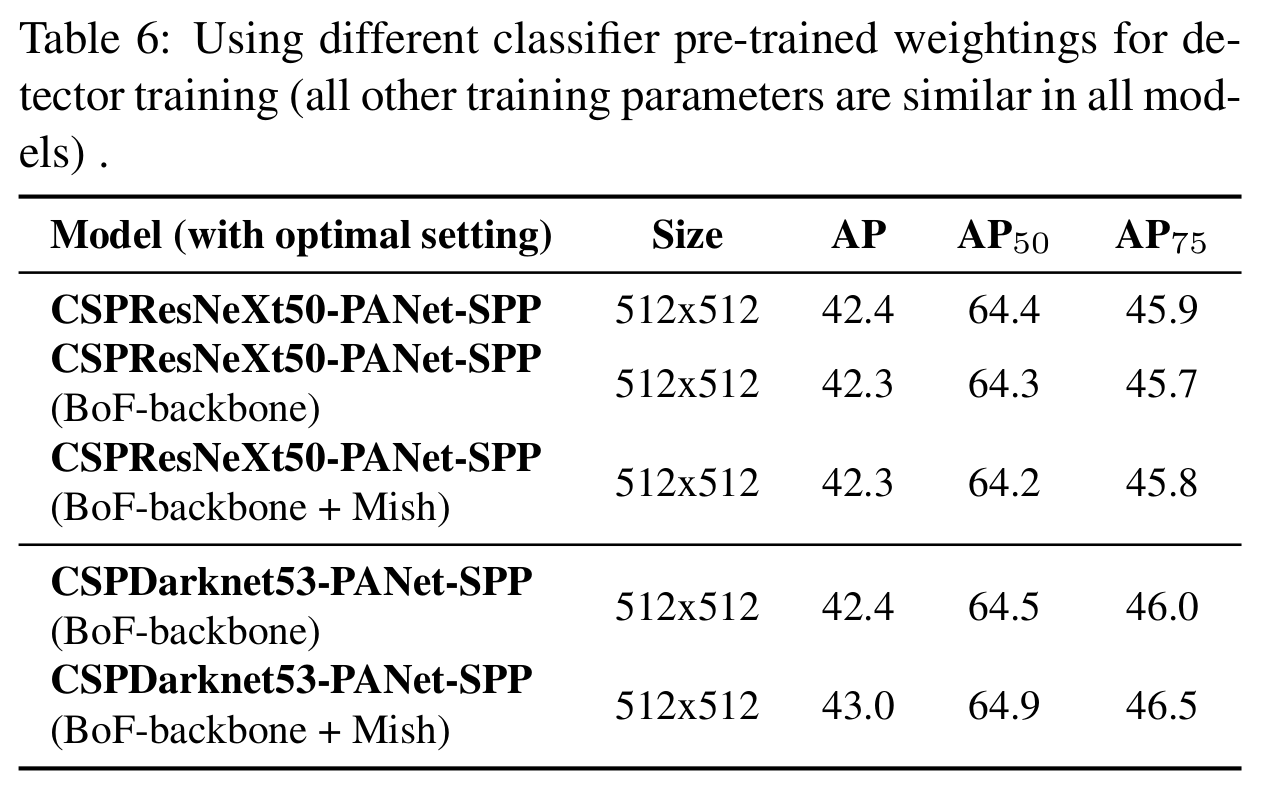
不同backbone和classifier的预训练参数对detector训练的影响
『不同classifier预训练参数对detector的影响』
不同mini-batch尺寸对detector训练的影响
『不同mini-batch尺寸对detector训练的影响』
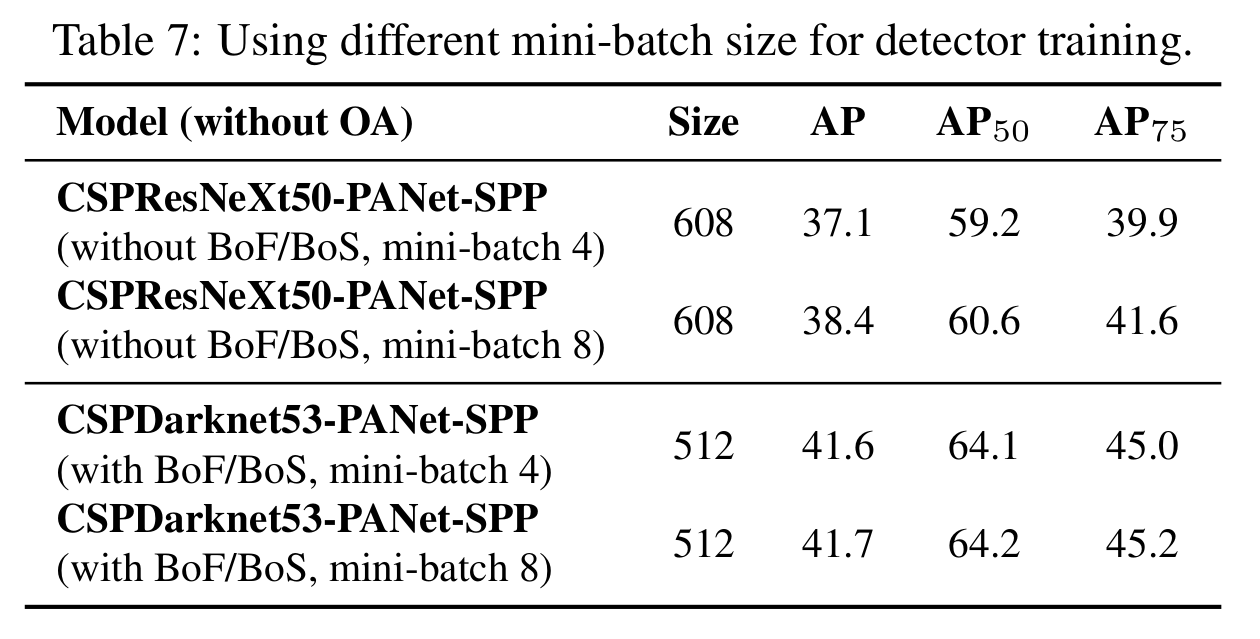
实验发现,mini-batch size对detector的效果几乎没有影响。
note
backbone在分类器里的最佳,在检测器并不一定最佳。
CSPResNeXt50+BoF,Mish分类时↑ 检测时↓CSPDarknet53+BoF,Mish分类时↑ 检测时↑
作者感谢了一位大佬提供的思路:使用遗传算法选择超参数,解决网格敏感度的问题。