背景
yolo v1的出现提供了一个one stage的算法,同年没多久就被SSD等在准确率和速度上欺负。时隔一年多,作者基于时代的进步,加入了多个先进的工作,使用多个trick取长补短优化模型。
效果
1.优化yolo模型。
2.预测超9000类别。
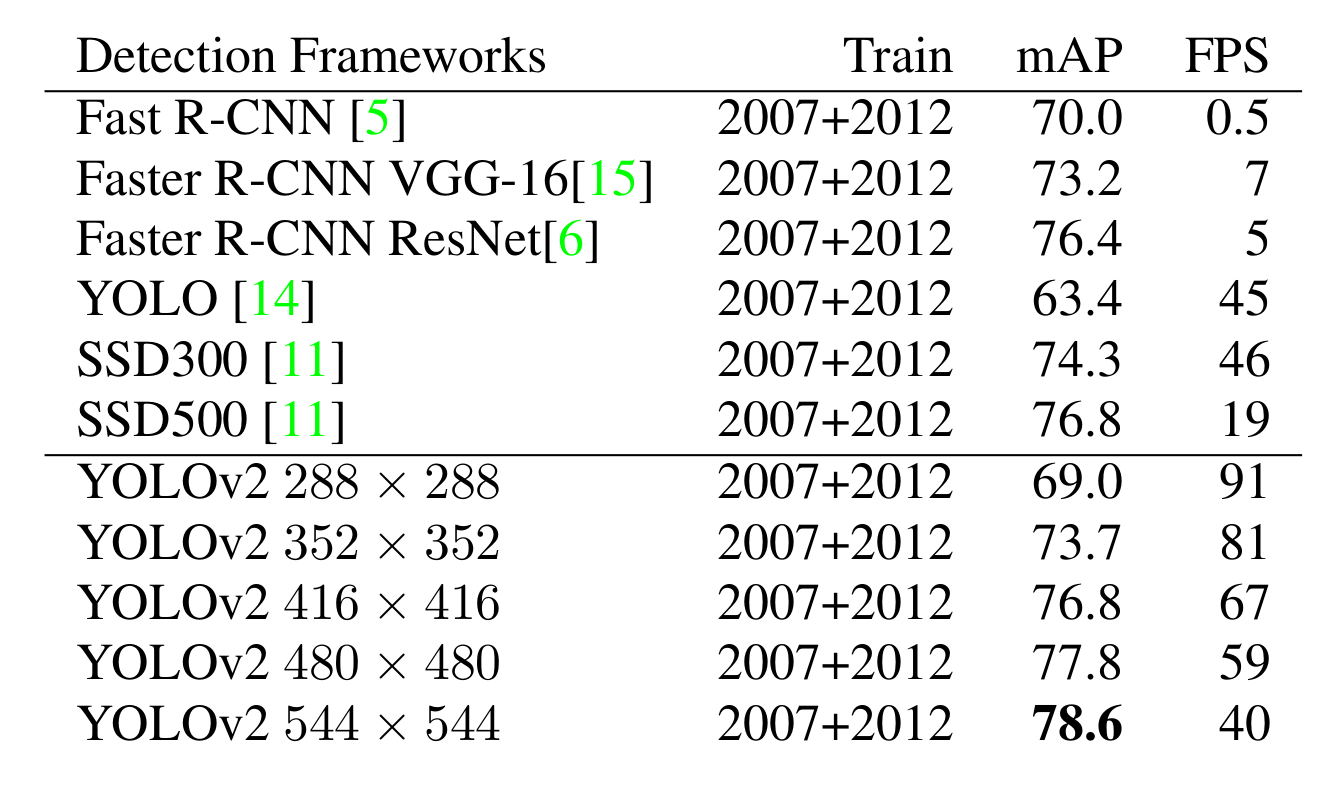
『官方实验』
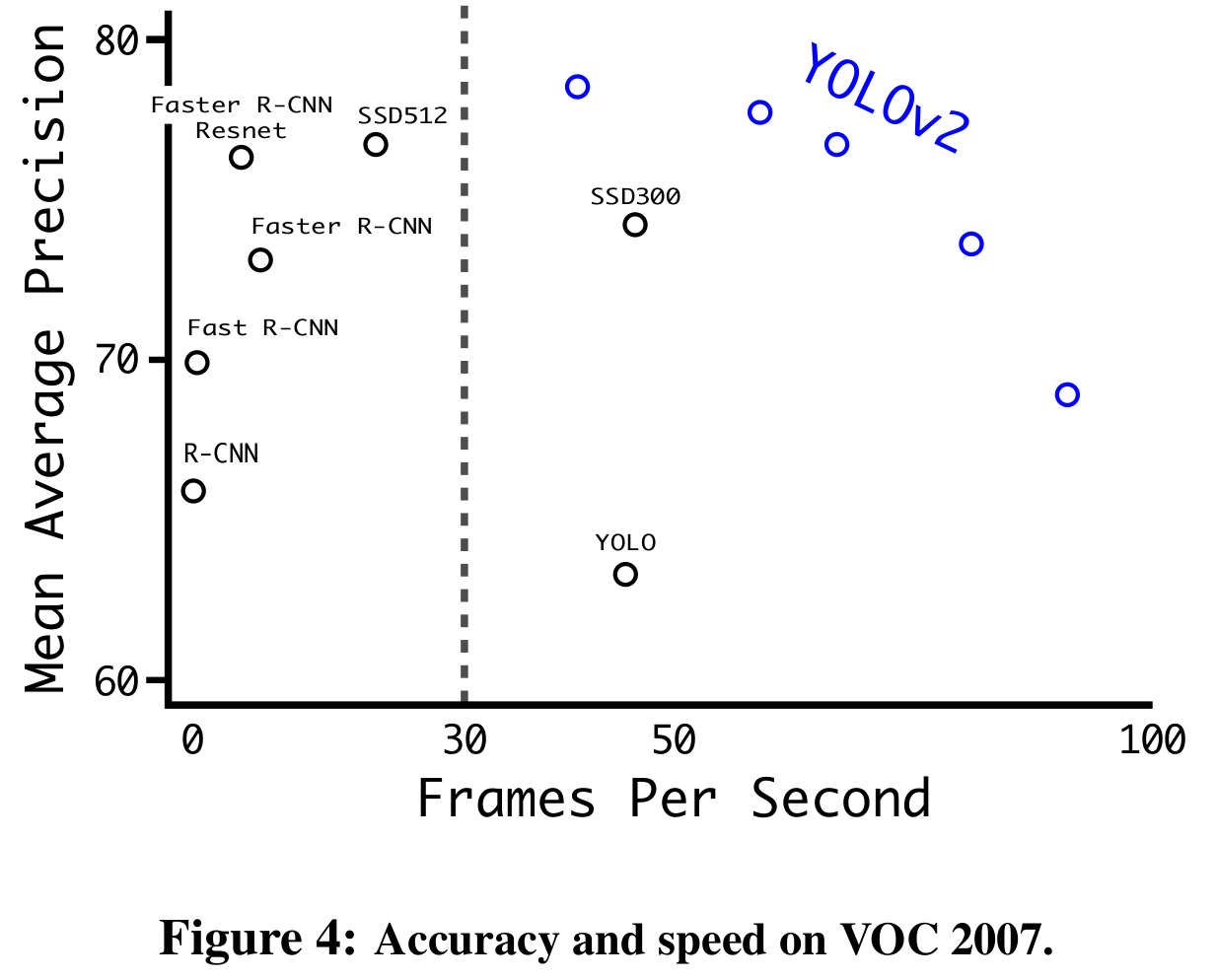
非常理想的在各方面远超其它模型。
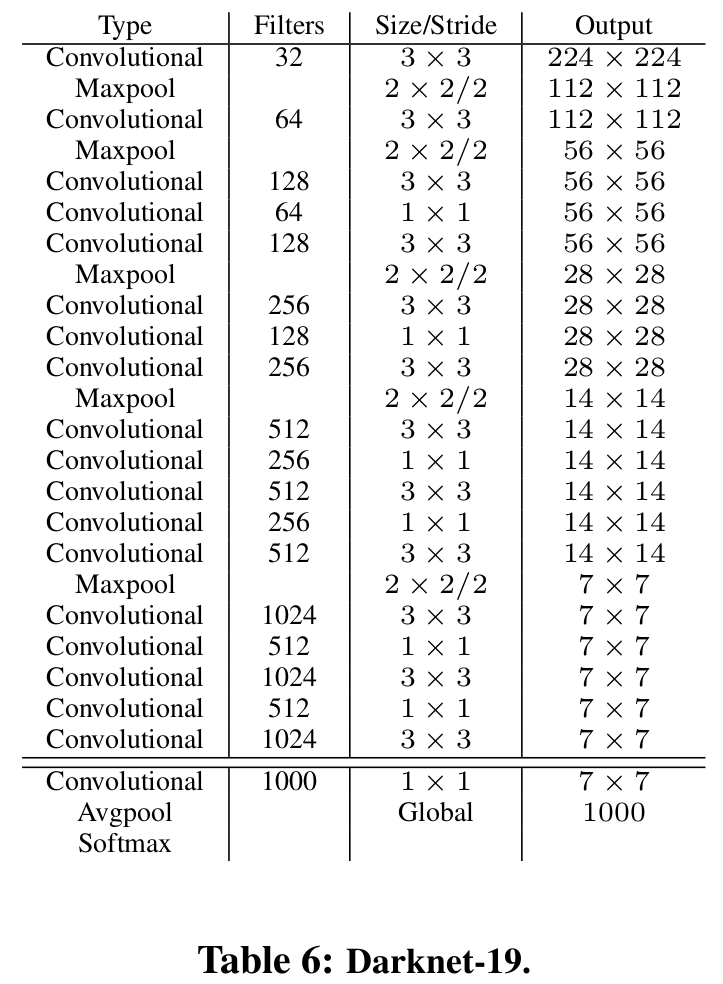
网络
『网络结构』
思路
yolo v1主要的缺点:
- 与Fast R-CNN做误差分析,yolo v1有大量的定位误差。
- 与region proposal方式比,yolo v1的recall比较低。
『10个trick』

1.batch norm?
2.4% mAP ↑
用于解决internal covariate shift问题,防止梯度消失、加速收敛等。
作用:
- 提升收敛速度
- 正则化模型
有正则化效果,就可以不使用dropout了。
2.hi-res classifier?
3.7% mAP ↑
不足:因为yolo v1的分类网络是224x224的,而detector网络是448x448,这意味着大于224x224分辨率的图片分类,分类器并没有在更高的分辨率中获得好处。
优化:先让分类网络在以224x224分辨率训练,再以448x448分辨率训练10个epoch进行调整。
3.convolutional?
convolutional + anchor boxes => 0.3% mAP ↓
recall ↑
移除全连接层,采用卷积预测。使用全卷积后,输入的图片不再固定,可以任意变化,只要大于步长。
输出的分辨率从64倍缩小,变为32倍。输出分辨率从7x7变为了13x13。由此,输入分辨率也调整为416x416。
4.anchor boxes?
convolutional + anchor boxes => 0.3% mAP ↓
recall ↑
不足:yolo v1是让每个cell预测那片的坐标,不像Faster R-CNN哪样预测的是anchor box的偏移。
优化:也采用anchor box方式。
- 预测偏移比简单的预测坐标更容易使网络学习。
- 从先预测目标是否存在后,再分类。 -> 为每个anchor box都预测类别和对象存在与否。
- yolo v1只预测98个盒子(
7x7x2),采用anchor box后,预测超千个。(解决了1代无法检测密集目标的问题)
5.new network?
0.4% mAP ↑
大多detector使用VGG-16,它是强力的,精确的分类器,但没必要那么复杂。
yolo v2使用基于GoogleNet的自制网络,比VGG-16快,参数更少,精度稍微差点。
使用全卷积分类,19层conv + 5层maxpool。
最终,top-5准确率高于VGG-16和GoogleNet…
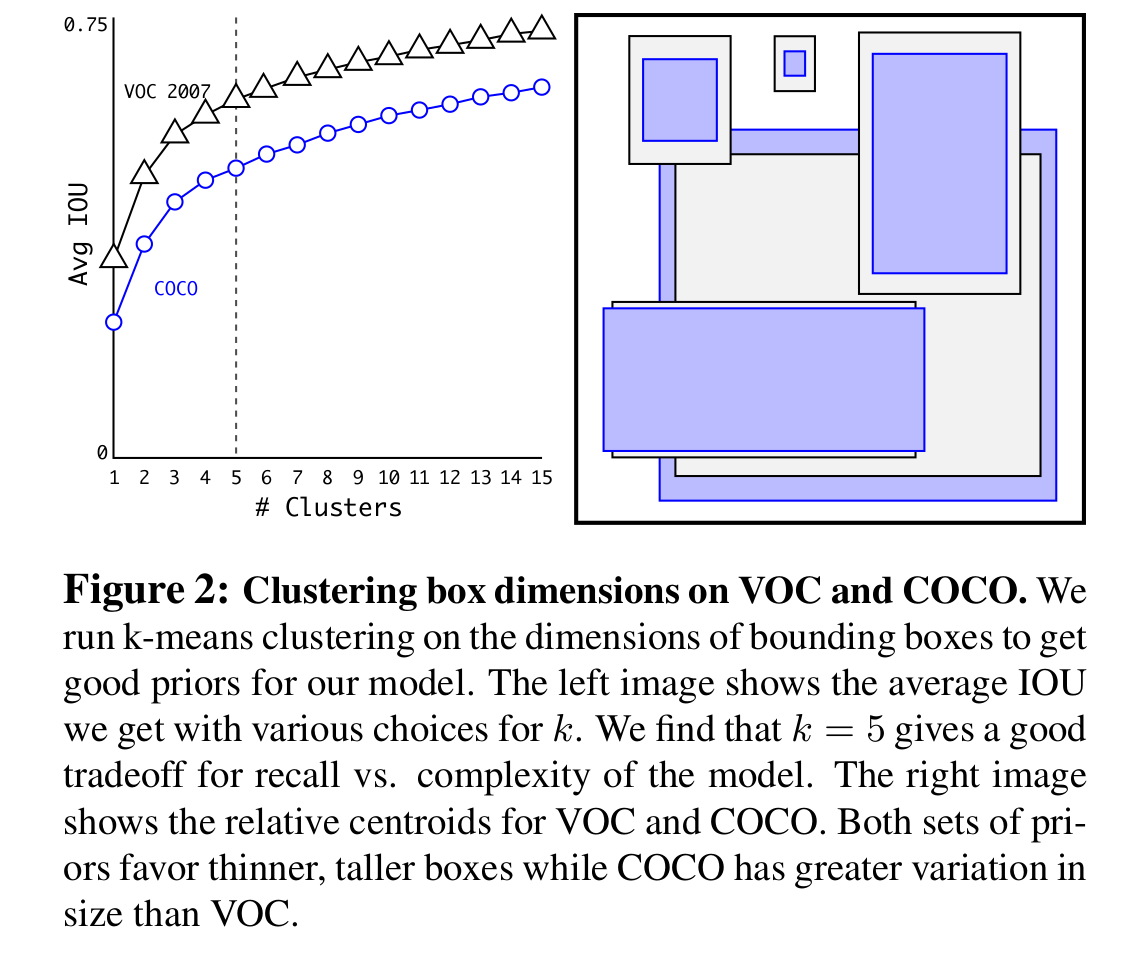
6.dimension priors?
dimension priors + location prediction => 4.8% mAP ↑
手选的anchor box尺寸,虽然网络会学习调整预测的box去变得合适,但好的anchor box的挑选,能让网络学习更容易,检测更好。
yolo v2采用k-means从数据集中挑选合适的anchor box尺寸。
而且,不使用标准的欧几里德距离的k-means,因为越大的box比小盒产生的更大的误差,而想要的IOU的值。故采用IOU评估。
以下k的选取,k=5是模型复杂度和recall的交易,通过k-means挑选出来尺寸,有更多矮、宽、高、瘦的box。
『anchor box的尺寸和数量选择』
7.location prediction?
dimension priors + location prediction => 4.8% mAP ↑
约束到区域的预测,参数的学习更容易。
『边界盒坐标的计算方式』
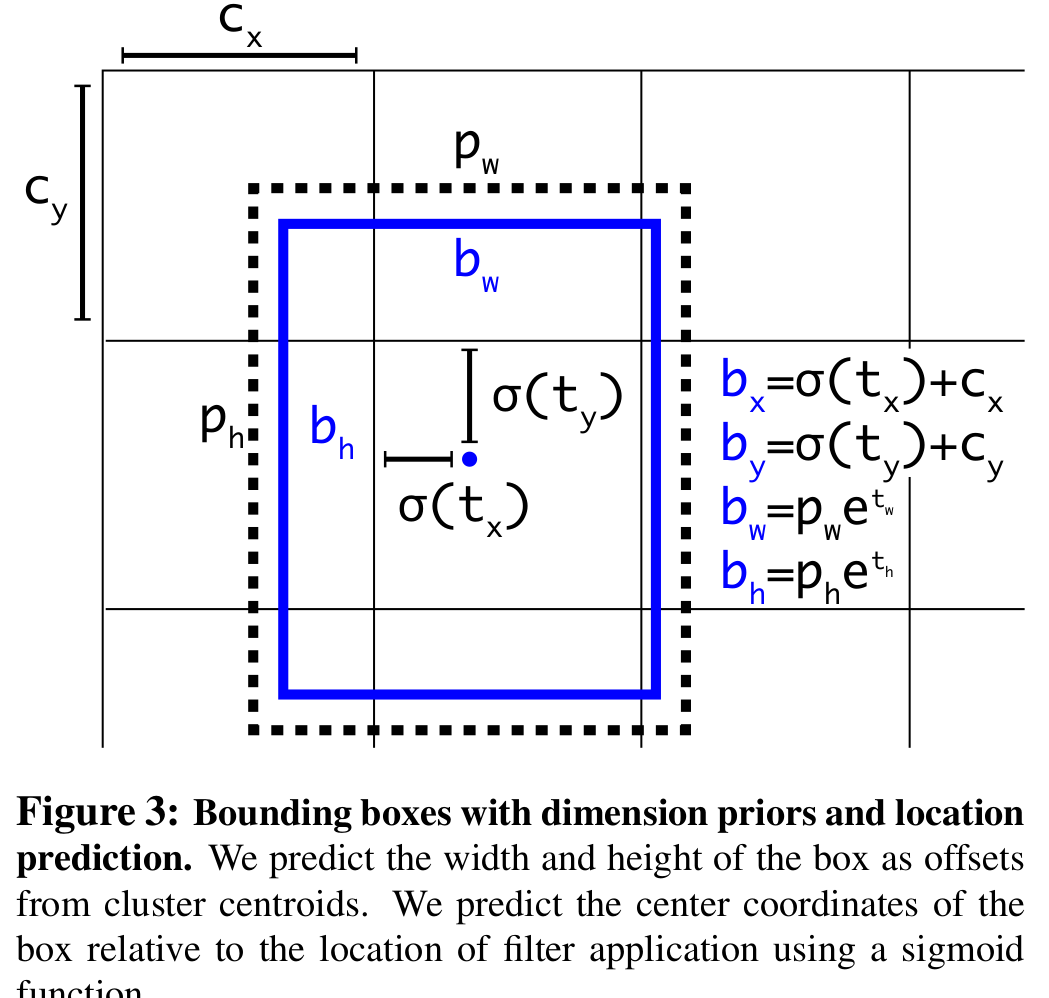
($c_x$, $c_y$)是bounding box的左上角的坐标。
8.passthrough?
1% mAP ↑
将最后一个pool之前,26x26x512大小的特征图,reshape到13x13x2048,passthrough到分类卷积(filter数量为1000)之前的特征图13x13x1024合并为13x13x3072。
9.multi-scale?
1.4% mAP ↑
只使用卷积和池化后,网络能运行不同的分辨率。
每训练10代就,随机选取一个新的分辨率。
因为下采样是32倍,图片尺寸也选用32的倍数。{320, 352, …, 608}
10.hi-res detector?
1.8% mAP ↑
分辨率越高,mAP越高,FPS越低。
『不同输入分辨率的图片的mAP和FPS』