背景
- HOG/DPM使用滑动窗口方法均匀的对整张图片分类。
- R-CNN使用proposal方式,先提出可能的区域,再分类。(后续还有:精修边界框,过滤重复,重新打分。)复杂的pipeline流水线是缓慢和难优化的,因为每个独立的模块都需要分别训练。
- Fast R-CNN,容易将背景块当作对象,因为它看不到更大的上下文。
效果

贡献
- 统一模型,速度快,无复杂的pipeline。
- end-to-end的模型(不同于滑动窗口),可以让模型在训练中,联系整个图像上下文,学到其中蕴含的关系。(应该指的是:分类和定位之间的关联,也许会得到某些对象应该出现在场景的哪些地方。(车应该在地面上,云应该在天上))(天上的车会被定位时放弃掉?)
- 统一模型 + yolo做了更多的定位误差,减少了对背景的误判。(是Fast R-CNN的一半)
缺点
- 比较靠近的物体,小目标,识别能力较差。(因为1个网格只预测2个bbox,1个网格也只预测一个类)
- 长宽比的泛化能力不行。
- 准确性不如最先进算法。(one stage基本都比two stage准确率低)(作者归因于大部分在于定位问题)
网络
『参考GoogLeNet,24层卷积,2层全连接』

思路
以VOC数据集为例,B=2,C=20。
训练
- 运行网络。结果输出为7x7x30的矩阵。
- 通过confidence打分,判断这些网格是否包含对象,以及重合度多高。
- 对这些网格,计算损失。
对于损失函数的细节解释:
- 第1行和第2行是定位损失,第3行是对是否含对象的置信度损失,第4行是不含对象的置信度损失,第5行是分类损失。
- $\lambda_{\text {coord}}$: 4xB维度的localization error和20维的classification error同等重要显然是不合理,通过这个系数调整权重。
- $\mathbb{1}_{i j}^{\text {obj}}$: 挑选第i个单元格中,第j个bbox负责预测。
- $\sqrt{w} , \sqrt{h}$: 调整大小box对偏差的敏感性。(相同像素的偏差下,小box显然比大box更不能忍受)
- $\lambda_{\text {noobj}}$: 一张图中,大部分单元格可能都不包含object,导致样本不平衡。在训练优化模型时,梯度跨越大,不稳定。通过该系数调整权值平衡。
- $\mathbb{1}_{i}^{\text {obj}}$:挑选有object中心落入单元格i中,则该单元格负责预测该类别。
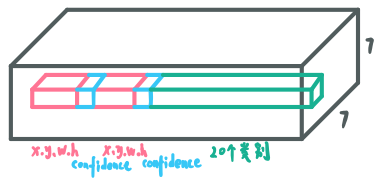
ps:预测的输出是一个SxSx(Bx5+20)=7x7x30(当是VOC数据集时)的矩阵。
- 7x7是划分的单元格,我们要求的是
ground truth box的中心落入那个单元格,那个单元负责该对象的预测。输出的x,y是与单元格的相对位置。 - 30是由(x,y,w,h,confidence)*2 + classes组成的,取B=2是指,每个单元格输出2个预测的bbox。
『预测输出的矩阵构成』
测试
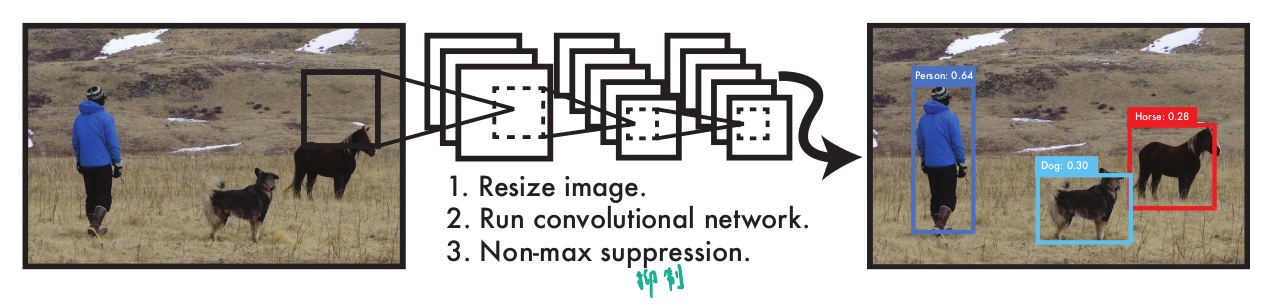
- 运行网络。得到7x7x30的结果。
- 将每个网格预测的2个bbox的confidence得分 * 分类的概率。(7x7x2 = 98个值)(不存在IOU的值)
- 设置阈值过滤,nms去重。
『test的步骤』
细节
训练细节
- 1.网络前20层使用,预训练模型。后4层卷积+2层全连接。
- 2.使用448x448分辨率的图像输入。
- 3.预测(坐标xywh,置信度conf)*B,类别概率c。
- 4.预测的bbox归一化到0~1。x,y为相对单元格的偏移,w,h为想对于整张图片的比例。
- 5.最后一层使用线性激活,其它层使用reaky-relu。
- 6.优化器平方差误差。(容易优化,然而不好到达最大平均精度)
- 7.定位误差和分类误差权重相同,这不好。
- 8.通常一副图中,大部分网格不包含对象,这会将这些单元格的confidence分数
push到0。加入不含对象的网格的loss来平衡。 - 9.定位损失↑,分类损失↓。
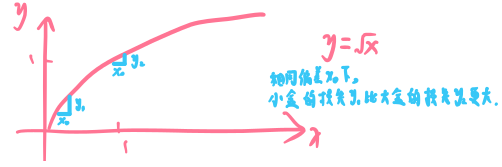
- 10.大盒和小盒偏移相同的像素,对于大盒影响不大,而对小盒有明显偏差。使用平方根做损失,可以提高小盒的损失。
『y=x^(1/2)函数图像,展示对不同尺寸的box,在相同的偏移下的损失量』
- 11.每个单元格预测B个边界盒(VOC数据集中,取B=2),不同边界盒能得到更多尺寸,比例,类别。
- 12.第一个全连接后,使用dropout。
附图理解
『中上表示所有单元格预测的所有bbox,中下表示每个颜色代表不同类别。(很容易被误导成单元格只预测这个一块小区域再组合的。)』
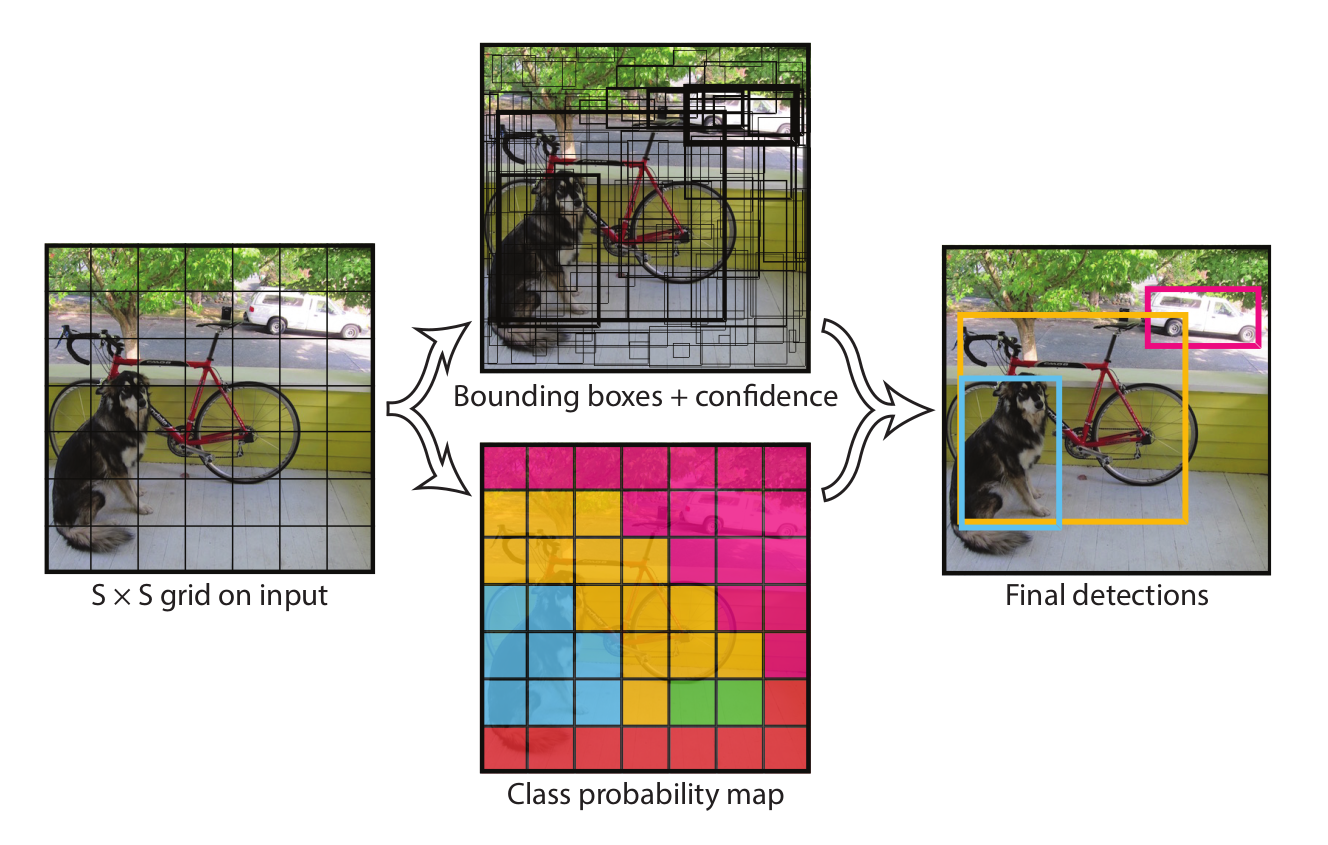
『每个单元格是如何预测的』

more
note
误区:
划分为7x7的网格,总觉得采用类似SSD的方式,每个网格预测包含一块区域,然后由这个网格这部分涉及到的神经元去运算。就会联想到,这么一小块网格在定位时由于只有一小部分图像信息,连定位都是问题。
-> 实际上,由于最后一部分全链接的存在,其实,这里划分的网格是输出的结果部分7x7x30,而不是输入的图像划分的7x7。预测输出的结果已经是包含了整个图像的信息,其中每个网格的划分,只是说这个网格对应的位置区域是预测到的 对象的中心落入这个单元格,故由这个单元格去处理(这个处理也很具有误导性,其实就是对象中心落入这个单元格,就把预测的结果输出到这个位置的单元格而已)。