背景
- 在原图上做假设边界框,需要太多计算。
- 对标YOLO,同是Single Shot,精度和速度更好。
效果
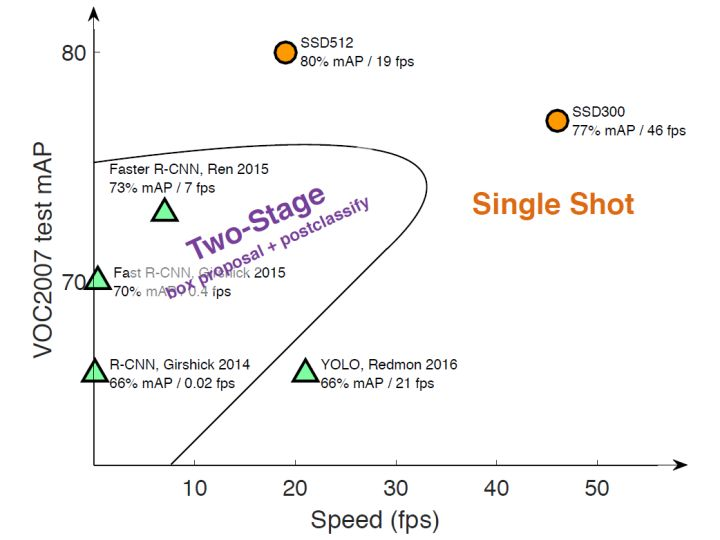
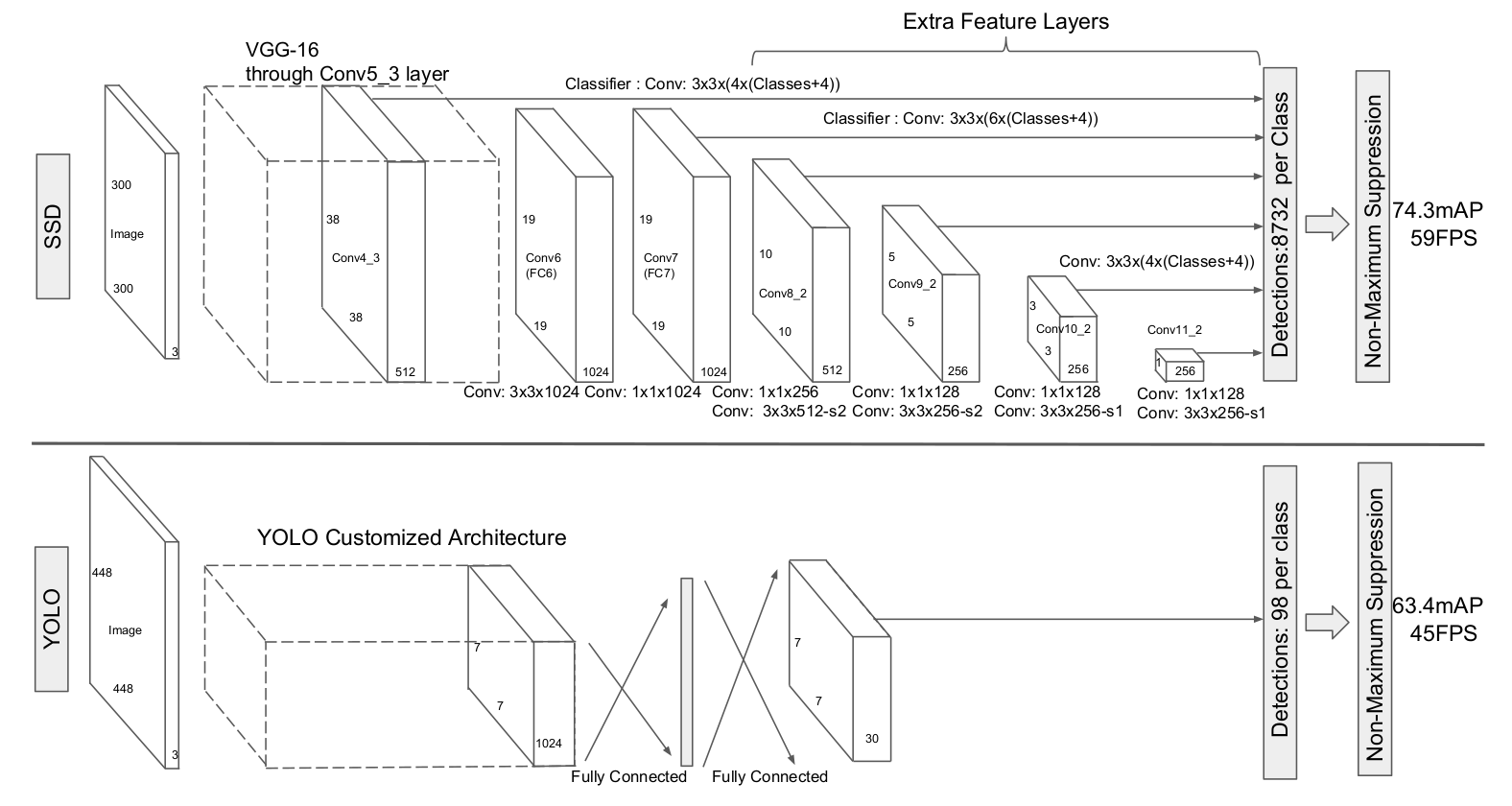
- SSD:300x300分辨率,74.3% mAP,59 FPS。(VOC2007数据集)
- YOLO:300x300分辨率,63.4% mAP,45 FPS。(VOC2007数据集)
『目标检测网络速度精度对比』
『SSD512识别COCO数据集』

贡献
- 1.使用不同比例的特征图预测。
- 2.使用卷积分类。
- 3.速度比yolo快。
- 4.端到端,高速度和精度。
- 5.对比试验。
网络
『使用的是VGG16』
『MultiBox是如何在feature map上操作』
思路
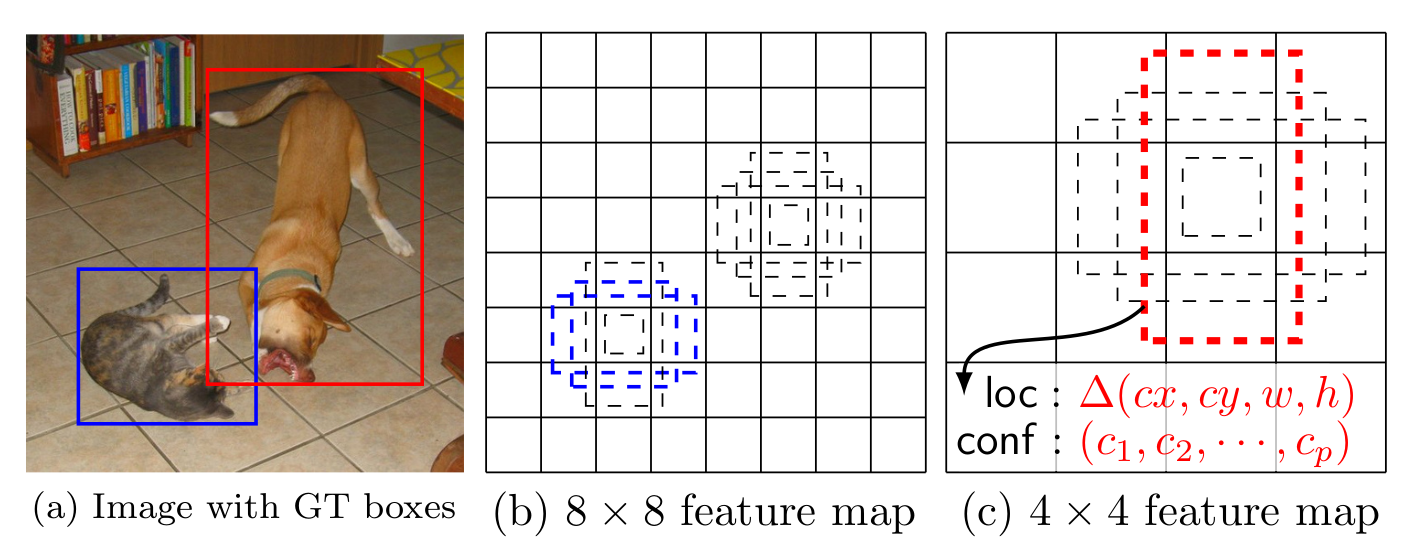
多个比例特征图识别 (Multi-scale feature maps for detection)
渐近的减小特征图的尺寸,使用不同尺寸的特征图做预测。(6层)
YOLO只操作单一尺寸的特征图。
卷积预测分类 (Convolutional predictors for detection)
对于$m \times n$尺寸$p$通道的特征图,使用卷积核为其分类打分。
YOLO使用全连接做预测分类。
默认框,长宽比 (Default boxes and aspect ratios)
设有c个分类,其中背景也算一类。
特征图分为$m \times n$尺寸的单元,每个单元有k个默认框(k种不同比例大小的框)。
每个单元有4个位置偏移值$\Delta(c x, c y, w, h)$。
于是总共有$(c+4) k$个过滤器,对于$m \times n$尺寸的特征图,共有$(c+4) k m n$个输出。
SSD预测输出的是对这个默认框的偏移量,为的是使用合适大小的边框框出对象。
论文中的默认框(default box),按理解,应该是预置的边界框,类似滑动窗口的窗口。
本文中的默认框与Faster R-CNN中的anchor boxes相似。然而本文应用它们到几个不同分辨率的特征图。
细节
匹配策略 (Matching strategy)
匹配默认框和标签的jaccard重合度(iou)大于阈值(0.5)。
损失函数 (Training objective)
总损失
\(L(x, c, l, g)=\frac{1}{N}\left(L_{\operatorname{conf}}(x, c)+\alpha L_{\operatorname{loc}}(x, l, g)\right)\)
L = 定位损失(loc) + 置信度损失(conf)。
- N:默认框匹配(iou>0.5)的正样本数量。
- c:置信度预测值。(分类类别的概率)
- l:预测框位置(预测相对于默认框偏移量)。
- g:位置标签。
- $\alpha$:权值系数。
定位损失
定位使用的是L1损失,多分类使用的是softmax损失。
L1损失: \(L_{l o c}(x, l, g)=\sum_{i \in P o s}^{N} \sum_{m \in\{c x, c y, w, h\}} x_{i j}^{k} \operatorname{smooth}_{L 1}\left(l_{i}^{m}-\hat{g}_{j}^{m}\right)\)
$x_{i j}^{p}={1,0}$:匹配第i个默认框与p类第j个标签框的指示器。
使用L1而不是L2是为了2方面限制梯度:
- 当默认框与标签框差别过大时,梯度值不至于过大。
- 当默认框与标签框差别过小时,梯度值足够小。
分类损失
softmax损失: \(L_{c o n f}(x, c)=-\sum_{i \in P o s}^{N} x_{i j}^{p} \log \left(\hat{c}_{i}^{p}\right)-\sum_{i \in N e g} \log \left(\hat{c}_{i}^{0}\right) \quad \text { where } \quad \hat{c}_{i}^{p}=\frac{\exp \left(c_{i}^{p}\right)}{\sum_{p} \exp \left(c_{i}^{p}\right)}\)
与Faster R-CNN相似,预测的是默认框中心$(c x, c y)$和宽高$(w, h)$的偏移量。
偏移量计算
偏移量的计算公式: \(\begin{aligned} \hat{g}_{j}^{c x}=\left(g_{j}^{c x}-d_{i}^{c x}\right) / d_{i}^{w} & \quad \hat{g}_{j}^{c y}=\left(g_{j}^{c y}-d_{i}^{c y}\right) / d_{i}^{h} \\ \hat{g}_{j}^{w}=\log \left(\frac{g_{j}^{w}}{d_{i}^{w}}\right) & \quad \hat{g}_{j}^{h}=\log \left(\frac{g_{j}^{h}}{d_{i}^{h}}\right) \end{aligned}\)
选择默认框的比例和长宽比 (Choosing scales and aspect ratios for default boxes)
选取的特征图是:Conv4_3,Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2
每层特征图的默认框比例计算: \(s_{k}=s_{\min }+\frac{s_{\max }-s_{\min }}{m-1}(k-1), \quad k \in[1, m]\)
- m:选取做预测的特征图数量。
- k:第几个特征图。
- $s_{\min }$:最小比例。(0.2)
- $s_{\max }$:最大比例。(0.9)
选用的长宽比: \(a_{r} \in\left\{1,2,3, \frac{1}{2}, \frac{1}{3}, s_{k}^{\prime}=\sqrt{s_{k} s_{k+1}} \right\}\)
其中Conv4_3,Conv10_2,Conv11_2层仅使用4个默认框,不使用长宽比为3,1/3的默认框。
SSD总计预测:38 x 38 x 4 + 19 x 19 x 6 + 10 x 10 x 6 + 5 x 5 x 6 + 3 x 3 x 4 + 1 x 1 x 4 = 8732 个边界框。
计算长和宽: \(w_{k}^{a}=s_{k} \sqrt{a_{r}}, \quad h_{k}^{a}=s_{k} / \sqrt{a_{r}}\)
设置默认框中心为: \(\left(\frac{i+0.5}{\left|f_{k}\right|}, \frac{j+0.5}{\left|f_{k}\right|}\right)\)
- $f_{k}$ : 第k个特征图的单元数量。
- i,j: $i, j \in [0, |f_{k}|)$。
严重的负样本处理 (Hard negative mining)
因为在一张图像中,往往只有几个目标对象,所以大部分都是背景,被当作负样本,这将会导致严重的样本不平衡。
为了平衡样本,将所有的样本以分类的置信度排序,选取分数高的框,使负正样本比例为3:1。
数据增强 (Data augmentation)
- 使用原图。
- 裁减。
- 缩放。
- 水平翻转。
more
note
本文主要与yolo比较,创新点主要在使用卷积中的多层特征图做定位和分类,采用卷积做分类。