背景
- 以往做法,采用运动学分解目标,作为图模型表达。
- 以往做法,结合浅层鉴别模型,和手动设计表达。
效果

贡献
- 1.解决了对象的精确定位,和对象分类问题。
- 2.能够预测多个物体的边界框。
- 3.使用深度神经网络训练。
网络
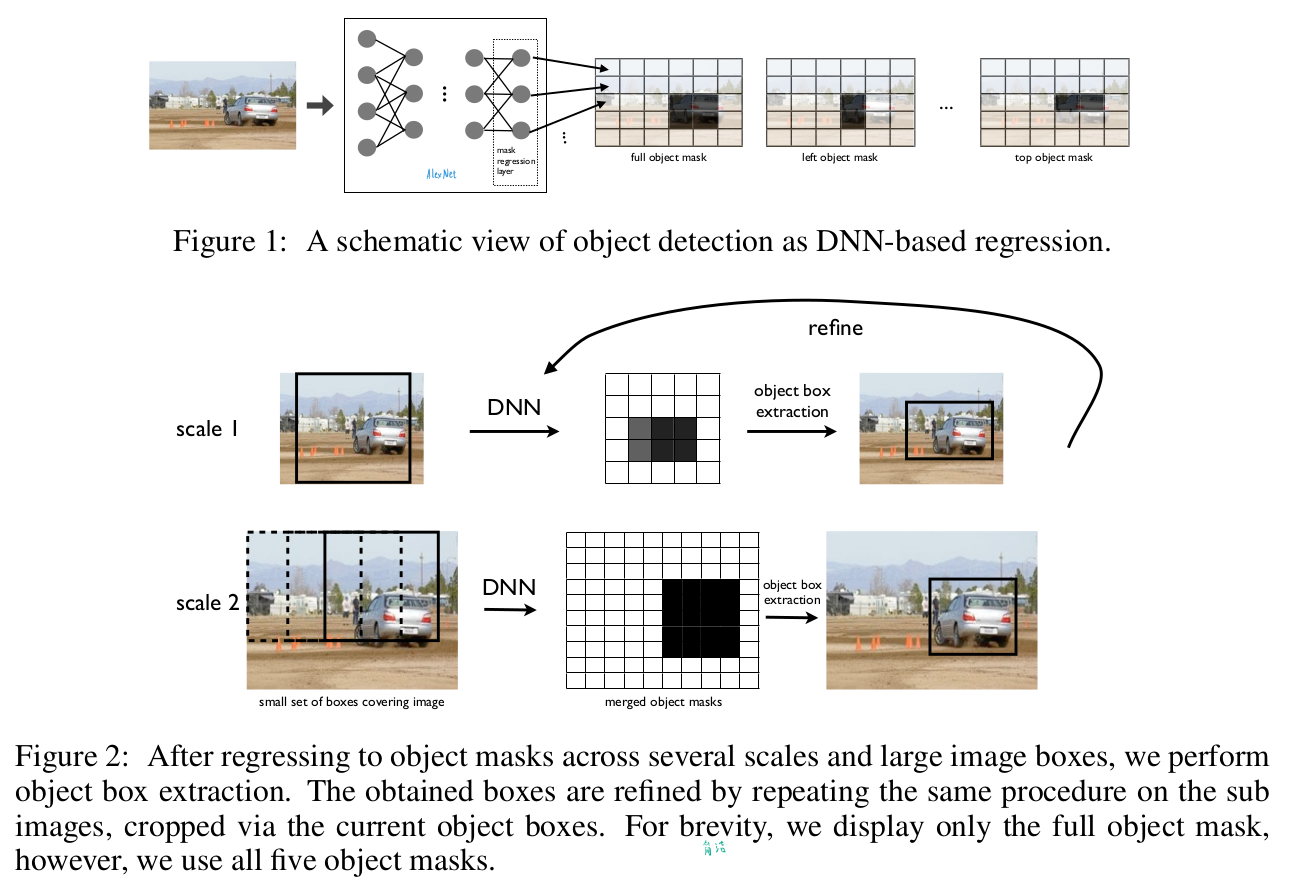
算法步骤:

思路
损失函数:
\[\min _{\Theta} \sum_{(x, m) \in D}\left\|(\operatorname{Diag}(m)+\lambda I)^{1 / 2}(D N N(x ; \Theta)-m)\right\|_{2}^{2}\]损失函数 = 平衡正负数据量 + DNN做深度神经网络计算预测目标相对于标签的误差
- $\Theta$:网格参数。
- 预测目标的二进制蒙版:$DNN(x ; \Theta) \in \mathbb{R}^{N}$
- N:像素的数量,$N=d \times d$。
- m:图片x的蒙版标签,$m \in[0,1]^{N}$。
- D:图片中包含标签的部分。
- $\lambda$:$\lambda$非零值一致性权值。因为相对于图像,对象较小,很容易使网络被简单的分配全零捕获网络。输错0的惩罚小于输错1的,鼓励非零预测。(宁可认错,不愿错过)
网络接受225x225的图片,预测蒙版尺寸为$d \times d$(d=24)。
细节
通过DNN生成的掩码进行精确的对象定位 (Precise Object Localization via DNN-generated Masks)
问题:小的对象对神经元的影响非常小,因此难以辨识。
多个蒙版实现可靠的集中 (Multiple Masks for Robust Localization)
\[m^{h}(i, j ; b b)=\frac{\operatorname{area}(b b(h) \cap T(i, j))}{\operatorname{area}(T(i, j))}\]
- $m^h$:蒙版的5种切分。
- bb:(bounding box)边界盒。
- h:$h \in { \text{full, bottom, top, left, right}}$。
- T(i, j):表示预测的(i, j)那部分的图像。
- d1:图像的高。
- d2:图像的宽。
- d:预划分的蒙版尺寸。
为处理多个接触目标,使用多个mask。
计算预测的掩码T和滑动窗口bb之间的比例。(前景像素的比例)
每个mask需训练单独DNN,它们的定位器可以共享参数。
DNN输出中的对象集中 (Object Localization from DNN Output)
计算标签m和滑动窗口bb的重合量作为打分。
计算5种scale的mask,和这5种mask附加周边的分数差。(为了彻底搜索可能的bb)
计算的值大于0.5,再使用Alexnet对其分类:
\[S(bb, m)=\frac{1}{area(bb)} \sum_{(i, j)} area(bb \cap T(i, j))\]
- S:bb和m重合的分数。
彻底地搜索可能的bb:
\[S(bb)=\sum_{h \in halves} (S(bb(h), m^h) - S(bb(\overline{h}, m^h)\]
- $\overline{h}$:围绕bb的矩形区域。
滑动窗口步骤:使用9种(0.1,…,0.9)图像比例的对象框。用k-means聚类数据集的对象框,获取10种横纵比。以步长为5个像素滑动窗口。将此公式计算值大于0.5的,使用Alexnet分类。保存分类,剪枝。
DNN定位器的多尺度优化 (Multi-scale Refinement of DNN Localizer)
问题:前2个方法已经解决定位识别(大致定位),现需要优化得到不大不小的框。
步骤1-滑动窗口
3个图像的scale,可以看作3个尺度为1x,2x,4x大小的窗口去扫描图片。步长控制在让每个窗口的overlap少于20%。最后对每个scale得到5个{full, bottom, top, left, right}detection结果,共15个detection结果。
步骤2-refine
对上述15个detection的结果,将bb扩大1.2倍后,重新应用到网络。(如图2)
论文认为,这个方法与滑动窗口不同,因为需要鉴定的滑动窗口少。
train
对于每个类别,都训练2个DNN,一个用于mask的定位模型,一个用于分类模型。
先训练分类模型,在用分类模型做pretrain训练定位模型。
计算交集公式Jaccard-similarity:$J(A, B) = \frac{A \cap B}{A \cup B}$
将J < 0.2,视为负样本,J > 0.6,视为正样本。
more
note
本文将深度神经网络应用到目标检测中。